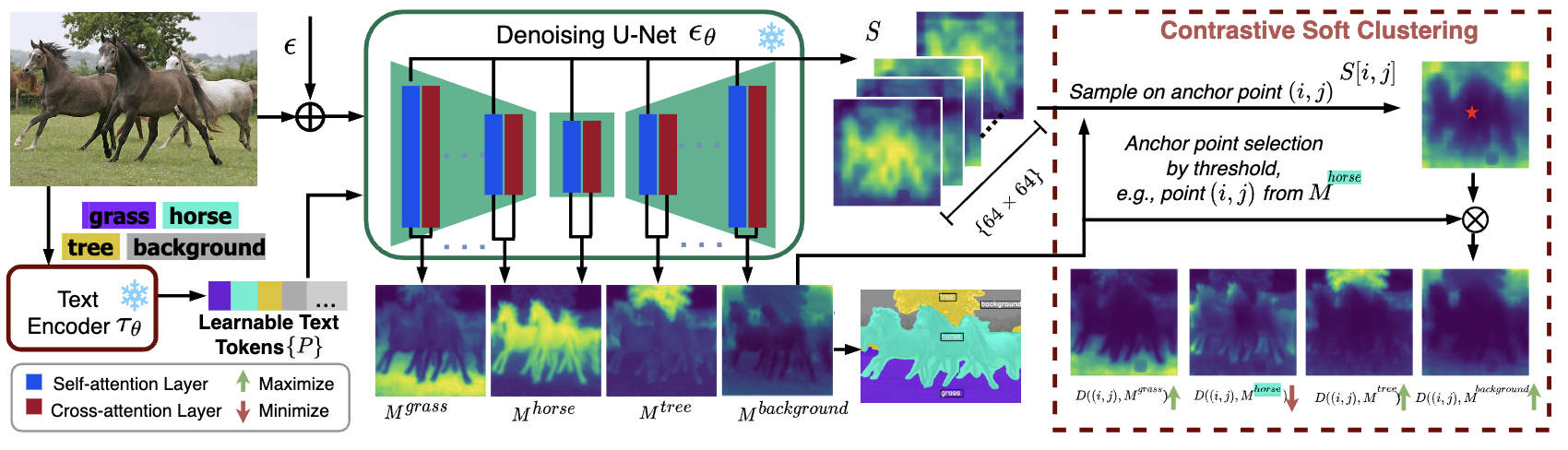
The precise visual-textual correlations embedded in the attention maps derived from text-to-image generative diffusion models have been shown beneficial to open-vocabulary dense visual prediction tasks,e.g., semantic segmentation.
However, a significant challenge arises due to the distributional discrepancy between the context-rich sentences used for image generation training and the isolated class names typically available for visual discrimination. This discrepancy in the richness of textual context limits the effectiveness of diffusion models in capturing accurate visual-textual correlations.
To tackle this challenge, we propose a novel approach called InvSeg, a test-time prompt inversion method that leverages per-image visual context to optimize the context-insufficient text prompts composed of isolated class names, so as to associate every pixel and class for open-vocabulary semantic segmentation. Specifically, we introduces a Contrastive Soft Clustering (CSC) method to derive the underlying structure of images
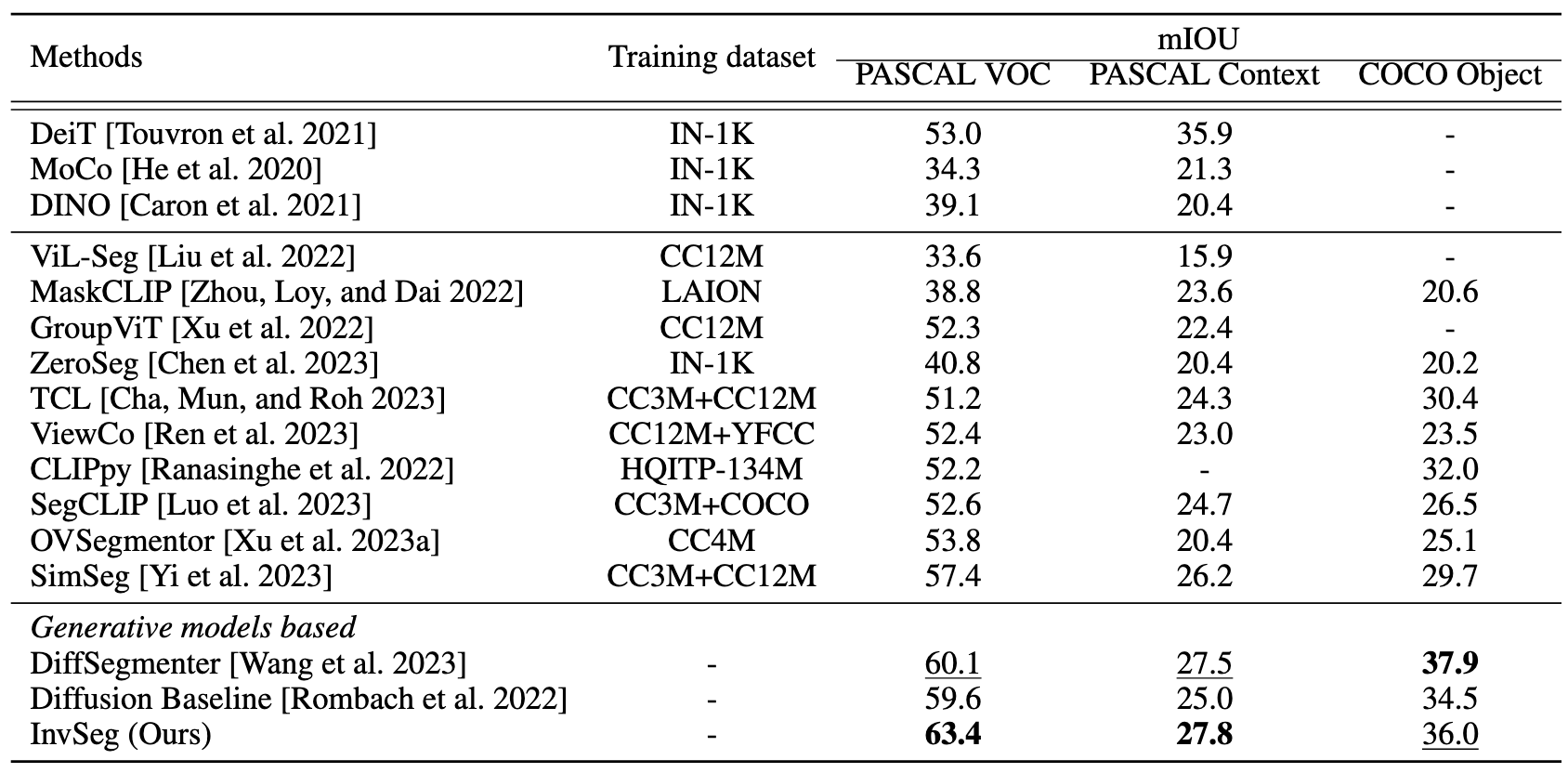
according to the assumption that different objects usually occupy distinct while continuous areas within visual scenes. Such structural information is then used to constrain the image-text cross-attention for calibrating the input class embeddings without requiring any manual label or additional training data. By incorporating sample-specific context at test time, InvSeg learns context-rich text prompts in embedding space to achieve accurate semantic alignment across modalities. Experiments show that InvSeg achieves state-of-the-art performance on the PASCAL VOC and Context datasets.